2 minutes
Spring AI: A Pleasant Tool for Building LLM-Based Web Services
In a short gap between two jobs, I started working on a simple idea for a creative, multi-modal (text-to-text and text-to-image) AI-based web application. I had been tracking the open-source development of the Spring AI project, and thought it would be the perfect opportunity to evaluate the project for my idea.
While life has gotten in the way of my finishing of the project so far (the frontend is essentially non-existent still :skull:), it has been a genuinely fun experience to use tools for building AI-backed applications. I find that their methods of usage breed creativity, and the lack of limitations makes the ideation process quite enjoyable.
The idea is to build something that sparks creativity in response to small bits of user input, generating a multi-modal creation by chaining multiple small pieces together in succession. By doing this, you are introducing more creativity with each additional link, feeding the whole chain into the new prompt at each step. For a project like this, creative prompting is surprisingly more important to getting good results than anything related to engineering quality.
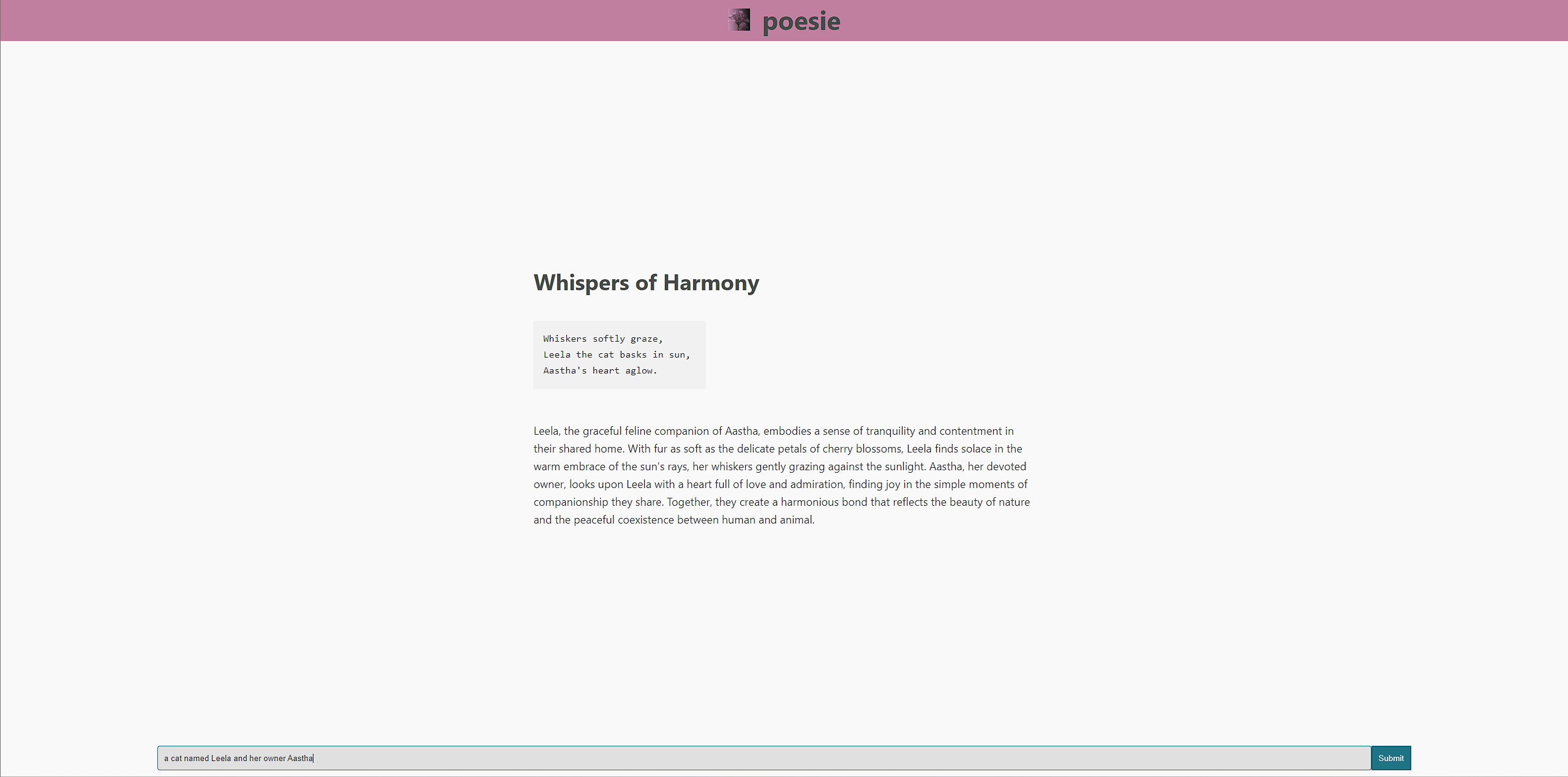


Here are links to the backend and frontend codebases on GitHub. I’m hoping to get a working demo up sometime in the near future before my focus inevitably shifts to other projects.
235 Words
2024-05-15 00:00